
Overview
React websites pose a big challenge when it comes to SEO. This best practices guide provides an introduction to what the challenges are and how to deal with them in order to rank higher.
Challenges with SEO for React Websites
a. The use of React-based Single Page Applications
Since the start of the World Wide Web, websites worked in such a way that the browser needed to request each page completely. To simplify, the server generates HTML and sends it back on every request.
Even if the next page has a lot of the same elements (menu, sidebar, footer, …), the browser will still ask for the entire new page and re-render everything from the ground up.
This causes a redundant information flow and additional stress on the server that needs to fully render each page instead of supplying only the required information.
With the advancement in technologies, the requirement for faster loading times increased. To resolve the issue with the full page loading time, developer communities came up with JS-based Single Page Applications or SPA.
These websites do not reload the whole content on the website, instead, they refresh only the content that differs from the current page.
Such an application improves the performance of the website drastically as the amount of data being transacted is reduced. One good example of technology that can be used to create SPAs is ReactJS, which optimizes the way the content is rendered on the user’s browser.
b. Main SEO issues with SPA
Although SPAs improves the website performance to a considerable extent, there are certain inherent issues in this type of setup when it comes to SEO.
Lack of dynamic SEO tags
An SPA loads the data dynamically in selected segments of the web page. Hence, when a crawler tries to click a particular link, it is not able to detect the complete page load cycle. The metadata of the page which is in place for the Search engine does not get refreshed. As a result, your single page app cannot be seen by the search engine crawler and will be indexed as an empty page, which is not good for SEO purposes.
Programmers can solve this problem by creating separate pages (more often HTML pages) for the search bots, and at the same time work with the Webmaster to discuss how to get the corresponding content indexed.
However, this will increase the business expenses owing to the cost of developing additional pages and also make it difficult to rank websites higher on the search engines.
Search Engines may or may not run your JavaScript
Every Single Page Application relies on JavaScript for dynamic loading of the content in different modules of a webpage. A search engine crawler or bot might avoid executing JavaScript. It directly fetches the content that is available without allowing JavaScript to run and index your website based on this content.
Google made an announcement in October 2015 mentioning that they would crawl the JS and CSS on websites as long as they allow the crawlers to access them. This announcement sounds positive but it is risky.
If the content on a page updates frequently, crawlers should regularly revisit the page. Googlebot has something called a second wave of indexing. In this process, they crawl and index the HTML of a page first, then come back to render the JavaScript when resources become available.
This two-phased approach means that sometimes, JavaScript content might be missed, and not included in Google’s index. This can cause problems, since reindexing may only be done a week later after the content is updated, as Google Chrome developer Paul Kinlan reports on Twitter.
Indexing is delayed for pure client side sides. Google indexer is two-pass, first run is without js, then week later it’s with is (or there abouts)
— Paul Kinlan (@Paul_Kinlan) September 12, 2018
This happens because the Google Web Rendering Service (WRS) enters the game. After a bot has downloaded HTML, CSS, and JavaScript files, the WRS runs the JavaScript code, fetches data from APIs, and only after that sends the data to Google’s servers.
Although Google crawlers are smarter today and they allow execution of Javascript, one cannot decide solely based on a single search engine. There are other crawlers like Yahoo, Bing, and Baidu which see these sites without JavaScript as blank pages. To resolve this, one needs to create a workaround to render the content server-side to give the crawlers something to read.
Limited Crawl Budget
The crawl budget is the maximum number of pages on your website that a crawler can process in a certain period of time. Once that time is up, the bot leaves the site no matter how many pages it’s downloaded (whether that’s 26, 3, or 0). If each page takes too long to load because of running scripts, the bot will simply leave your website before indexing it.
Talking about other search engines, Yahoo’s and Bing’s crawlers will still see an empty page instead of dynamically loaded content. So getting your React-based SPA to rank at the top on these search engines is more or less nonexistent.
This also doesn’t account for site speed issues (which are a ranking factor) and poor user experiences for anyone with JS not functioning or turned off.
This is such an issue, that Google themselves have come out with an approved dynamic rendering recommendation:
Solutions for SEO of React-based SPA websites
There are 2 major ways to resolve the SEO issues being faced in the React-based SPA websites.
- Isomorphic React
- Prerendering
a. How does Isomorphic React help in SEO?
An Isomorphic Javascript technology based React website automatically detects if the JavaScript is disabled on the client side.
In a scenario where JavaScript is disabled, Isomorphic JavaScript runs on the server-side and sends the final content to the client. In this manner, all the necessary attributes & content are available when the page loads.
However, if JavaScript is enabled, it performs as a dynamic application with multiple components. This provides faster loading than traditional websites, a wider compatibility for older browsers and different crawlers, smoother user experience and the features of Single Page Application as well.
b. Solving the problem using Prerendering
One of these approaches is to pre-render your website with a service like Prerender that uses Headless Chrome to render the page in the same way as a browser.
Prerender will wait for the page to finish loading and then return the content in full HTML.
Just like Isomorphic JavaScript, search engine crawlers can be targeted specifically to use Prerender while other browsers can still render the page by themselves.
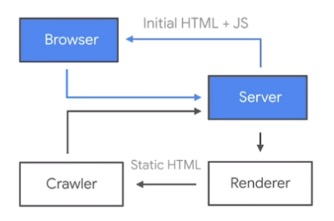
This approach has the following advantages:
- Allow the website to be correctly crawled by search engines.
- Easier to set up because we won’t need to make the codebase compatible with server-side rendering.
- Unlike Isomorphic Javascript, Prerender has less pressure on the server as it’s just a simple website rendering engine.
c. Google’s Own Dynamic Rendering Best Practices
Currently, Google has it’s own difficulties processing JavaScript and not all search engine crawlers are able to process it successfully or immediately. As a result, Google specifically recommends dynamic rendering as a workaround solution to this problem.
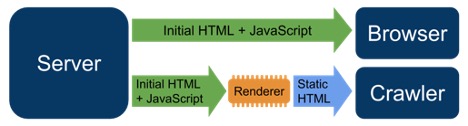
Dynamic rendering means switching between client-side rendered and pre-rendered content for specific user agents and helps to solve for Javascript features that are not supported by the crawlers.
d. Utilize the standard <a href> links in your HTML
One specific challenge not supported by crawlers is placing important content behind a JavaScript event.
Google may not follow a site’s “onclick” events at all. As stated by Moz, simply, “don’t use JavaScript’s onclick events as a replacement for internal linking.
Ensure consequential content is linked by <a href> links to ensure search engine discovery.
Additional tools to improve SEO of React Websites
React is not inherently optimized for search engines, so a set of tools can be used to create websites that are more Search Engine friendly.
Prerender.io
Prerender.io leans into recommendations by both Microsoft and Google serving crawlers a static HTML version of your Javascript website, without compromising your customers’ experience. The server can distinguish between human and robot, giving the human the full experience and the robot a lightweight HTML version.
Integrating Prerender is always a matter of a server-side request-rewrite. Your server needs to differentiate between a simple visitor and a bot request, and based on that it should either fulfill the request normally or rewrite the request to Prerender respectively.
With that said, generally, there are two ways to integrate Prerender:
- Integrated into the backend service using a so called ‘middleware’ provided by Prerender. This is analogue to the node.js middlewares – if familiar – but we have many languages covered, such as C#, Python, PHP, Ruby… etc. Middlewares are small code snippets that get executed upon every requests, but it only affects the response when a bot (e.g. Googlebot) user agent is detected. In this case it fetches the prerendered content from the Prerender.io cloud service and responds with that. Example middleware integration: https://github.com/prerender/prerender-node
- Integrated into the CDN in front of your servers – if any. In this case it’s not a middleware, but a set of well crafted rewrite rules that does the routing between your backend and Prerender’s cloud service as needed. Example CDN integration: https://docs.prerender.io/article/18-integrate-with-iis
In both cases the rewrite target is a very simple URL concatenation (https://service.prerender.io/<YOUR_URL>; that you can test easily, even without doing any integration, just issue the following curl command:
curl -H "X-Prerender-Token: <YOUR_PRERENDER_TOKEN>" https://service.prerender.io/https://www.movingtrafficmedia.com/
There are pros and cons for both methods: Integrating into the backend gives you more flexibility, as it runs actual code, so you have more granular control over what should happen and when.
But CDNs or caches in front of your servers may interfere with responses and may give you unwanted results. Integrating into the CDN makes this risk go away, but then not all CDNs are capable of routing the way needed.
Dynamic rendering is preferred by search engines and comes without an SEO penalty for cloaking content, making it the clear best choice.
React Router v4
React Router is a component to create routes between different components or pages. This makes it possible to build a website with a Search Engine friendly URL structure.
React Helmet
React Helmet is the most important component when it comes to the SEO of SPA. React Helmet is used to manage the metadata of the corresponding web document that is being served via React components. Being a library on top of React, React Helmet is also executable on the server-side as well as client-side.
The major advantage of React Helmet is the ease of integration without any major changes in the page coding.
React Snap
React Snap pre-renders a web app into static HTML and uses Headless Chrome to crawl all available links starting from the root. Zero configuration is the main feature. You do not need to worry about how it works or how to configure it.
Uses a real browser behind the scenes, so there are no issues with unsupported HTML5 features, like WebGL or Blobs and does not depend on React. The name is inspired by react-snapshot but works with any technology (e.g., Vue).
Conclusion
Single Page Applications created using React have excellent page load times and help in easier code management due to component-based rendering.
SEO of React-based SPAs takes some additional effort to configure the application. However, with the perfect tools and libraries in place, business owners and web communities are rapidly shifting to Single Page Applications for outstanding load times.




